Análisis
de la conversión serie-paralelo de una placa de red
Fecha: 22 de
marzo del 2020
Escenario
Analizando el escenario anterior apareció el interrogante: si los datos llegan por un cable uno detrás del otro, o sea en serie,
y los sistemas digitales trabajan con los datos en paralelo (bus de direcciones y datos), debe existir un mecanismo en las
placas de red que genere dicha conversión, y allá fuimos.
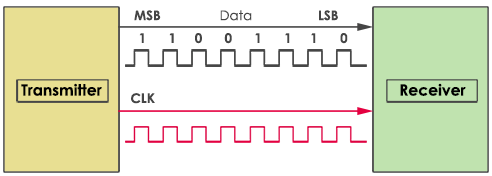
Cuando se transmite por ethernet nos imaginamos que un tren de ceros y unos van de una host a otro y allí queda, pero suele
ser mas complejo, por ejemplo que cada byte de transmite de derecha a izquierda (LSB to MSB) y no como lo leemos los humanos
de izquierda a derecha y entiendo que es justamente por el motivo que describiremos en este lab.
Esquema de bloques de una placa de red:
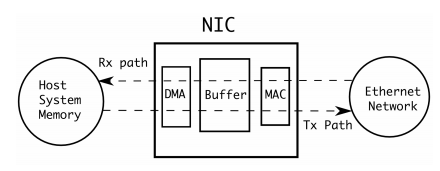
Fuente: Lund university
Una trama ethernet a su máxima capacidad de 1518 bytes se compone de aproximadamente 15200 bits llegando por el cable y debe
ser procesada por una placa de red para reenviarla a memoria a través del canal DMA y luego ser procesada por el sistema operativo.

Suponiendo una NIC con un sistema interno de 16 bits, una trama ethernet completa de 1518 bytes, luego de la decodificación 8B/10B son
12144 bits que se dividirán en 1518 bloques de un byte (8 bits) para ser “paralelizados”, puestos en un buffer (en 1518 partes), para analizar
la MAC destino y el CRC, y si está todo correcto, quitar la cabecera de layer 2 (12144-48-48-16-32 nos quedan 12000 bits), y para luego ser
enviados a una memoria (supongamos) de 32 bits, de a 32 bits por vez, o sea en 375 veces.
Suponiendo un sistema de 64 bits seran 188 operaciones de escritura en memoria.
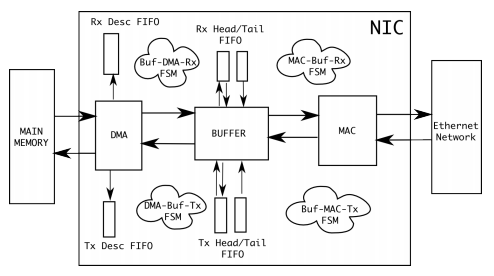
Fuente: Lund university
Una vez en memoria, todo el trabajo es de la CPU principal del equipo, del sistema operativo y la aplicación afectada.
Serial Input Parallel
Output (SIPO):
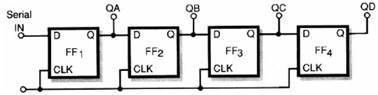
Fuente: www.incb.com.mx
Para entender cómo funciona este circuito comenzaremos desde la situación inicial donde todos están desactivados o con sus salidas Q a bajo nivel.
Inicialmente, se aplicará a la entrada de datos un nivel alto (1). Como podemos ver, es a entrada es hecha por la entrada D del primer flip-flop (FF1).
Con la llegada del pulso del clock a este flip-flop, cambia de estado y con este "almacena" el pulso aplicada a la entrada, que aparece en su salida.
Veamos que esta señal es almacenada con el flanco positivo de la señal del clock, cuando el nivel alto debe estar presente en la entrada del flip-flop.
En el siguiente pulso de clock, la entrada del primer flip-flop no tiene más alto nivel y por lo tanto FF1 no cambia estado, sin embargo, en la salida de
FF1 tenemos un nivel alto, y esta salida está conectada a la entrada del segundo flip-flop (FF2).
Esto significa que con la llegada del segundo pulso de clock, el nivel lógico de la primera salida se transfiere a la segunda salida.
A continuación, tenemos que, el bit 1 aplicado en la entrada cambia, pasando a la salida del segundo flip-flop.
Se aplica un nuevo nivel 1 en la entrada del circuito, al mismo tiempo que los primeros traslados al segundo flip-flop, el segundo se desplaza a
la salida del primer flip-flop.
Ahora que llega un tercer pulso clock, tendremos nueva transferencia y el nivel alto o el bit 1 se transfiere a la salida del siguiente flip-flop, es sea, FF3.
En otras palabras, en cada pulso de clock, los niveles existentes en las salidas flip-flop, ya sean 0 o 1, se transfieren al siguiente flip-flop.
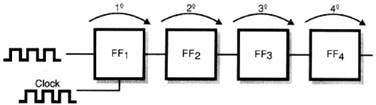
Por lo tanto, suponiendo que apliquemos, en secuencia, en la entrada de un registro como los niveles indicados 0101, tendremos la siguiente secuencia de
condiciones de salida para los flip-flop de un shift-register que usan 4 de ellos:
Veamos entonces que en el quinto pulso de clock, el primer pulso de clock, el primer nivel lógico, aparece a la salida del último flip-flop (FR4) y que, si leemos
la salida de los flip-flops, habrá registrado los niveles aplicados en la entrada: 0101.
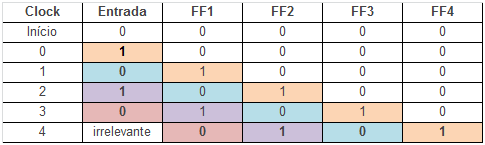
En un shift-register, después del número apropiado de pulsos del clock, que corresponde al número de bits que el contiene, puede almacenar estos datos.
Para "borrar" los datos registrados en un shift-register, todos a la vez, como se indica, sólo tiene que aplicar un pulso en la entrada CLEAR del shift-register y
todos los flip-flops tendrán sus salidas en el nivel bajo o 0.
MSB LSB LSB MSB
| | | |
El dato 10101111 realmente se transmite como <-- 11110101---, entonces tenemos que interpretar que se recibirá el primer 1 e irá al bit 1, 1 al bit 2,1 al bit 3,
1 al bit 4, 0 al bit 5, 1 al bit 6, 0 al bit 7 y 1 al bit 8 y luego del shift-register nos quedará 10101111.
Parallel Input Serial
Output (PISO):
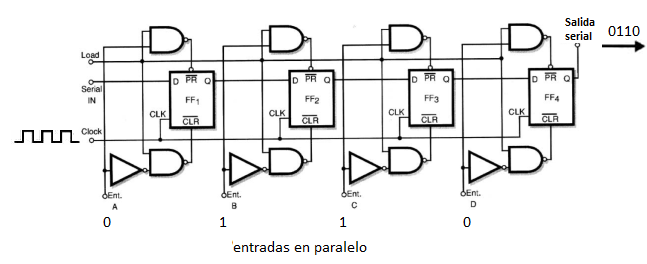
Los datos se colocan al mismo tiempo en la entrada, ya que funciona en paralelo. Por ejemplo, si vamos a almacenar los datos 0110, estos se aplican al mismo
tiempo en las entradas correspondientes de los flip-flops.
En el primer pulso de clock, los flip-flops "almacenan" estos datos. Así, los flip-flops que tienen nivel 1 en su entrada S pasan este nivel a la salida (FF2, FF3).
Por otro lado, los que tienen el nivel 0 en su entrada, mantienen este nivel en la salida (FF1 y FR4).
Esto significa que después del pulso del clock, las salidas de los flip-flop presentarán los niveles 0110, ahora con los siguientes pulsos de reloj “empujaremos”
los bits de las salidas desplazandolos de izquierda a derecha.
Probable escenario de 8 bits:
Esta es mi interpretación de como pueden llegar a ser los mecanismos para recibir un tren de bits en serie y poder almacenarlos en una memoria
buffer de 8 o 16 bits para luego enviarlos a memoria principal a traves del DMA.
Cómo es el proceso de envío desde el buffer a la memoria principal puede llevar todo otro análisis completo que escapa a este documento.
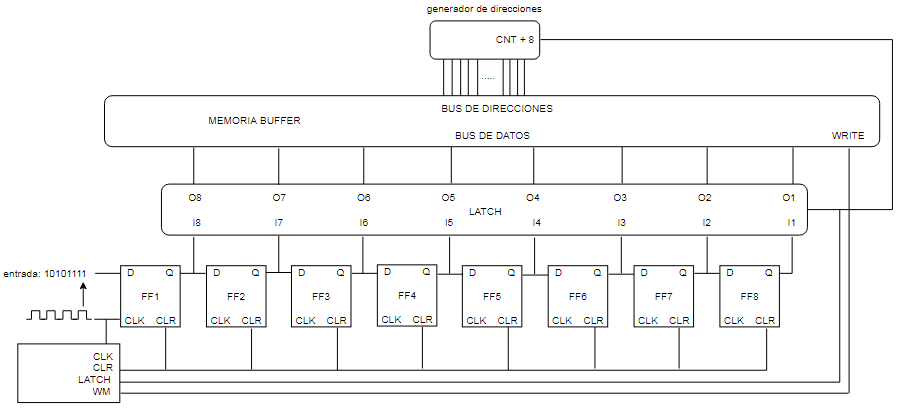
Llega a la placa de red un tren de bits que se decodifican 8B/10B, reemplazando los símbolos por los datos reales, estos entran al shift-register
y a la cuenta de 8 (bits) un latch retiene esa entrada en la salida, para que puedan ser escritos en una memoria buffer con la orden WRITE mientras
el shift-register se reinicia con CLEAR y procesa los próximos 8 bits.
En el próximo ciclo de escritura en memoria los datos se almecenarán en la dirección N+8 para que los bloques (bytes) queden contiguos y la trama
quede almacenada (aproximadamente) de la siguiente manera:

Detalle de una pastilla real que realiza todo este trabajo:
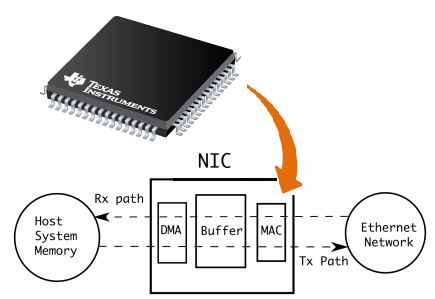
The TLK2501 performs data conversion
parallel-to-serial and serial-to-parallel. The clock extraction functions
as a physical layer interface device. The serial
transceiver interface operates at a maximum speed of 2.5 Gbps.
The transmitter latches 16-bit parallel data at
a rate based on the supplied reference clock (GTX_CLK).
TLK2501 Block Diagram:
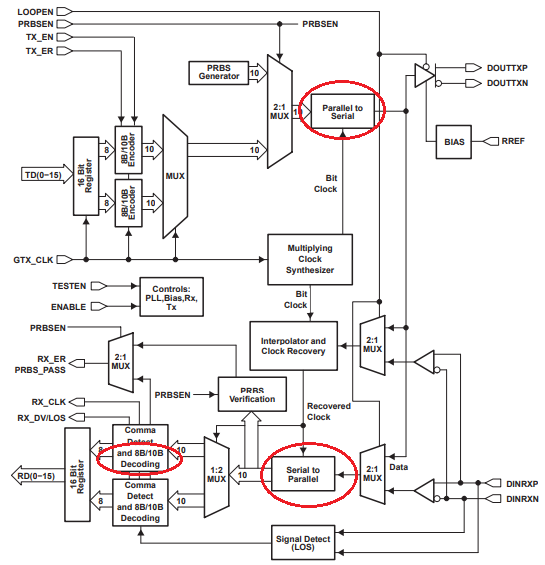
Fuente: Texas Instruments
Resúmen:
Este escenario (y el anterior) son mayormente interpretaciones mías de como son los procesos, con la ayuda de bibliografía
externa (basada mayormente en el libro Network Processors de Douglas Commer) y como pudimos ver, todo este diagrama
de bloques y circuitos hoy están ensamblados en una pastilla como el caso anterior.
Sólo me interesa transmitir el concepto y la inquietud de que sucede en los procesos de red, el resto queda a cargo de hasta
donde cada uno quiera llegar y estudiar, no hay límites.
(2020) Quarantine
makes me have binary visions
Rosario, Argentina