Midiendo
latencia (sin echarle la culpa a la red)
Fecha: 10 de abril del 2021
Escenario:
Muchas (pero muchas) veces al acceder a un servicio en particular y está
“lento” se le echa la culpa a la red.
La latencia es la suma de retardos parciales, desde que se envía un
paquete desde la aplicación hasta que
lo recibe el destinatario, también puede ser el round-trip desde que enviamos
hasta que recibimos.
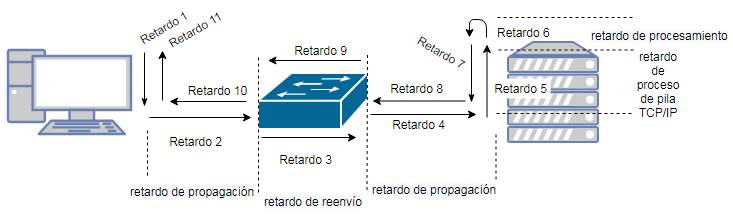
En esta prueba se ejecuta una prueba cliente/servidor con Netcat y
realizando un port mirroring en un switch
para obtener el RTT (round-trip time o tiempo de ida y vuelta ) de la
consulta/respuesta solo del servidor,
descartando el resto de latencia que pueda aportar la red (si existiese).
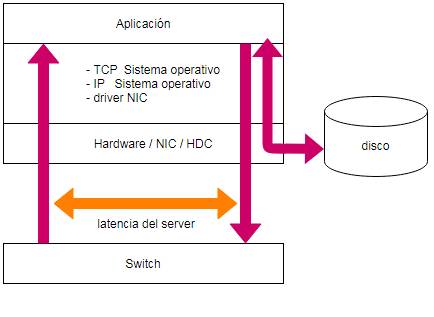
Muchas veces la latencia involucrada en un servicio en particular puede
deberse a N factores, tales como
carga de procesadores, memoria, acceso a disco, inestabilidad del sistema
operativo o de la aplicación misma.
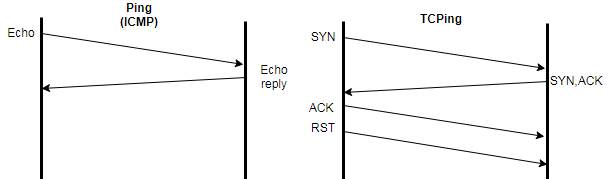
Para darnos una idea de manera sencilla, por ejemplo “tirarle un ping” a un
server (en realidad al sistema operativo)
es muy diferente que “pegarle” a la aplicación (que corre sobre el sistema operativo), observemos
la diferencias:
1.- Verificación inicial:
1.1.- Mediante ICMP:
C:\>ping 192.168.17.243 (le pegamos al sistema operativo)
Haciendo ping a 192.168.17.243 con 32 bytes de datos:
Respuesta desde 192.168.17.243: bytes=32 tiempo<1m TTL=63
Respuesta desde 192.168.17.243: bytes=32 tiempo=2ms TTL=63
Respuesta desde 192.168.17.243: bytes=32 tiempo=1ms TTL=63
Respuesta desde 192.168.17.243: bytes=32 tiempo=1ms TTL=63
Estadísticas de ping para 192.168.17.243:
Paquetes: enviados = 4, recibidos
= 4, perdidos = 0
(0% perdidos),
Tiempos aproximados de ida y vuelta en milisegundos:
Mínimo = 0ms, Máximo = 2ms, Media = 1ms
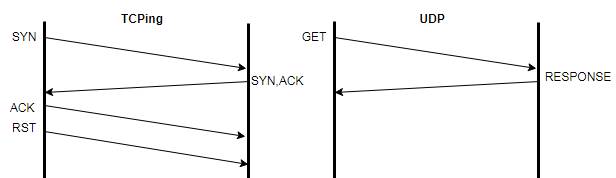
1.2.- Mediante TCP:
C:\>tcping 192.168.17.243 1234 (le pegamos a la aplicación en el
port 1234)
Probing 192.168.17.243:1234/tcp - Port is open
- time=11.336ms
Probing 192.168.17.243:1234/tcp - Port is open
- time=13.353ms
Probing 192.168.17.243:1234/tcp - Port is open
- time=7.985ms
Probing 192.168.17.243:1234/tcp - Port is open
- time=13.666ms
Ping statistics for 192.168.17.243:1234
4
probes sent.
4
successful, 0 failed.
Approximate trip times in milli-seconds:
Minimum = 7.985ms, Maximum = 13.666ms, Average = 11.585ms
C:\>
Esta última prueba también le “pegaría” al sistema operativo ya que es sólo
un acceso al port TCP que
utiliza la aplicación (comunmente llamado el socket) y no la aplicación misma que
procesa y devuelve
un dato propiamente dicho (alojado en memoria o en disco), pero sirve para
determinar la diferencia en
ver o medir la latencia con un ping
o un tcping.
Como parte de la latencia, el sistema operativo tiene que abrir un socket y
realizar las reservas de recursos
(alocar buffers en memoria) porque asume que la comunicación seguirá, antes de enviar el SYN/ACK.
El RST enviado es un aviso de descarte de dichos recursos, de lo contrario
la sesión queda en TIME_WAIT.
2.- Pruebas con tráfico UDP:
El tráfico TCP implica cierta carga burocrática (handshacking, ACK, etc)
que puede aportar cierta latencia,
cuando queremos bajar esos valores de RTT y sabiendo que (como siempre) la red
estará funcionando de
forma confiable, podemos recurrir a UDP ya que prácticamente no tiene carga de
control.
En cierta oportunidad participé en reuniones donde se implementaría una
aplicación que distribuye datos
que requieren baja latencia (time is
money) y que son consultados desde varios hosts en forma simultánea.
La solución a esto fué multicast, con esto solucionamos varios posibles
problemas de latencia:
1.- En lugar de N sesiones TCP (una por cada host cliente) tenemos 1 sesión
UDP para todos (y todas).
2.- En lugar de TCP (y su burocracia) tenemos UDP (mas
austero en recursos) ya que para un único
stream de datos no podrían haber N acuses de recibos (ACK) por lo tanto,
directamente los omitimos.
Para esto también necesitamos que la aplicación corra en UDP, obviamente.
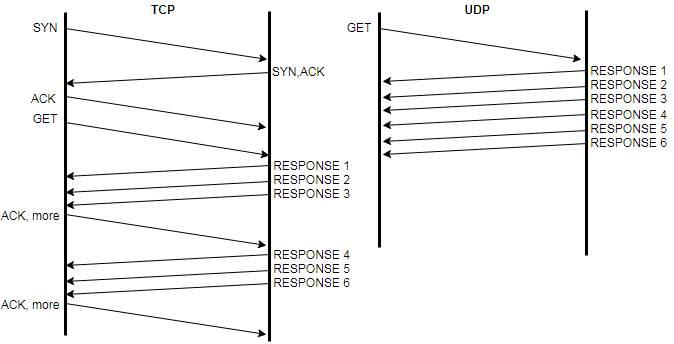
En la reunión como es de esperar surgió la pregunta: ¿como medimos el RTT
de UDP ??? y eso dió vida a
este laboratorio, ya que el RTT ICMP es fácil (un ping), el RTT TCP también con
(tcping), pero ¿UDP ?
No podemos siplemente hacerle “un telnet UDP a algo”.
Luego, recordando de años anteriores, alguna vez utilicé el Ghost Enterprise para clonar una imagen
de
disco en 20 PCs al mismo tiempo, y atando cabos, fué con la dupla multicast/UDP.
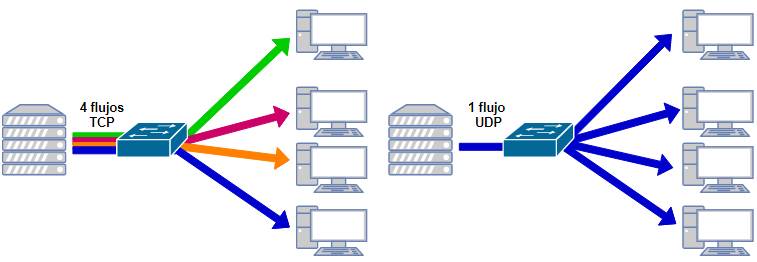
En el gráfico anterior el
multicast se comportaría como un broadcast, con flooding en todas las
interfaces
(pero
eso ya es otro tema que escapa a este laboratorio).
Recordemos, para esto la red debe ser 100%
confiable (no esperaría otra cosa).
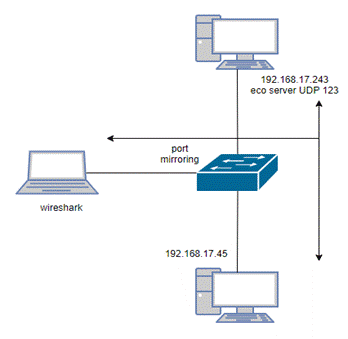
2.1.- Preparamos la escucha en el
server:
Al utilizar un port mirror, el switch hace una copia de todo el tráfico que
entra y sale de un port en particular
y lo reenvía a este prácticamente sin generar latencia extra y con resultados
bastante fieles.
Otro factor importante es el de la “latencia cero” en el host con Wireshark
(por ejemplo una instalación limpia,
que no tenga dirección IP (no metemos nosotros ruido en la red) y si es
Windows con el antivirus desactivado,
total al no tener dirección IP estamos aislados del mundo.
root@server:~$ ncat -e /bin/cat -k
-u -l 1234
Donde:
-e means it executes /bin/cat (to echo back what you type)
-k means keep-alive, that it keeps listening after each connection
-u means udp
-l 1234 means that it listens on port 1234
2.2.- Generamos la consulra en el
cliente:
root@cliente:~$ nc -u 192.168.17.243
1234
prueba (escribimos)
prueba (recibimos el eco)
2.3.-
Verificamos con Wireshark conectado en mirroring:
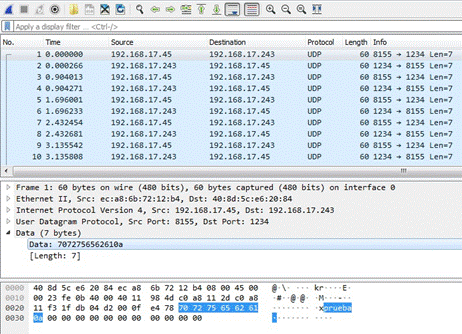
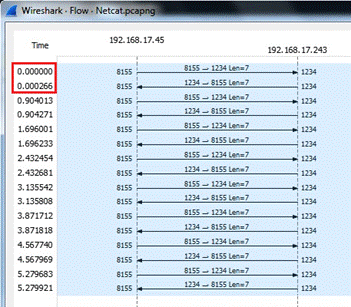
Podemos ver que el RTT es de 0.000266 segundos, o sea 266 microsegundos, contra los milisegundos de TCP.
No debemos olvidar que en TCP si un dato se pierde se puede volver a
solicitar de manera específica por el mismo TCP, en UDP si se pierde y la aplicación no lo reclama o no tiene la forma, el
dato se pierde. Es cuestión de costo/beneficio. (2021) Time is
money (again) Rosario, Argentina